注:想直接看解决问题的方法的可点击该传送门:解决方案
问题背景
我在源站上做了极限压缩,目标是让客户端拿到最小体积的文件,降低正在看这篇文章的你的流量消耗。但在这个月月初,我注意到有很多人的网页都遭到了恶意流量工具,甚至我自己的一台服务器也遭到了来自德国(主要)的网络攻击。这就是为什么我套上了 Cloudflare CDN(仅针对非中国大陆用户,毕竟 Cloudflare 在国内的访问速度…懂得都懂)。但是套上 Cloudflare CDN 后,我发现几个问题:Cloudflare 他老人家不听我的啊!我要极限压缩,他又不干,大概就是:
- 当有一个访客来到了我的博客,并请求了一个
gzip压缩效果更好的资源a。但实际上,这位访客直接下载到的并不是我源站上用gzip压缩过的内容,而是经 Cloudflare 重新压缩的gzip。 - 当又有一个访客来到了我的博客,并请求了一个
brotli压缩效果更好的资源b,那么他直接下载到的… 还真就是我源站压缩的! - 可如果这时候一个浏览器不支持
brotli的访客来到了我的页面,并请求了那个资源b,那么 Cloudflare 就会直接给我“截胡”,自己压缩了一遍 —— 即使效果并不是很好。 - 如果,还是这个访客,请求了一个
brotli压缩效果更好的资源c,而我的源站返回了使用zstd压缩过的内容,那么 Cloudflare 就会把这个zstd压缩过的传给客户端 —— 只要客户端他支持。 - 可这时候要是再来一个浏览器支持
brotli的访客过来请求了资源c,那么他收到的只会是我源站给的zstd压缩过的内容,而不是brotli,因为zstd的结果被 Cloudflare 缓存了! - 过了一会,一个访客来到了我的博客,请求了一个
deflate压缩更小的资源… 完了!我们的 Cloudflare 不认识他!于是这位访客如我的愿下载到了deflate压缩过的资源,但… 没有了Content-Encoding头,导致浏览器他不知道,就乱码咯。
或许会有人说:“这才多大个事?把你源站的 deflate 禁了不就行了?别的东西没用你的压缩就没用,你那能省几个流量?”
但… “量变”听说过不?(好吧其实就是我强迫症)
尝试探索
知道问题之后,我第一反应就是“问问 ChatGPT”,看看有没有现成的解决方案。可是问了之后… 基本上能给出大概操作方法,但每次都不能完全如愿,后面干脆就说“Cloudflare 会重新压缩,不可控”这种偏概念性的回答。
DeepSeek、Gemini 之类的也是类似的思路,基本上告诉我“你需要 no-transform、URL 重写、页面规则”等,但就是没啥效果。
但我怎么可能会这么容易放弃呢?
最开始我想的是,能否用规则,把客户端的 Accept-Encoding 请求头写到别处,把源返回的 Content-Encoding 也写到别处,再通过规则把它写回来。但经过测试,Cloudflare 的规则虽然是能动态修改响应头,但就是不让你改 Content-Encoding,一改就直接清空,哪怕你源服务器也返回了这个。那…还能怎么办呢?欸!前面 ChatGPT 它们不是教了我个叫 no-transform 的玩意吗?虽然不能完全实现“自动选择最小压缩内容”,有时候还会丢 Content-Encoding 头,但至少真就是源站返回什么,Cloudflare 就返回什么,那就…组合起来试试看!
具体的探索过程我就不详写啦,下面咱直接看怎么操作就行。
解决方案
首先先看 Cloudflare 上怎么配置
首先,我们需要前往 Scrape Shield 禁用掉 Cloudflare 的“电子邮件地址混淆技术”,防止 Cloudflare 修改你的 html。当然,如果你需要这个功能的话,那可以选择留着,只是 html 文件可就不能保证压缩效果咯~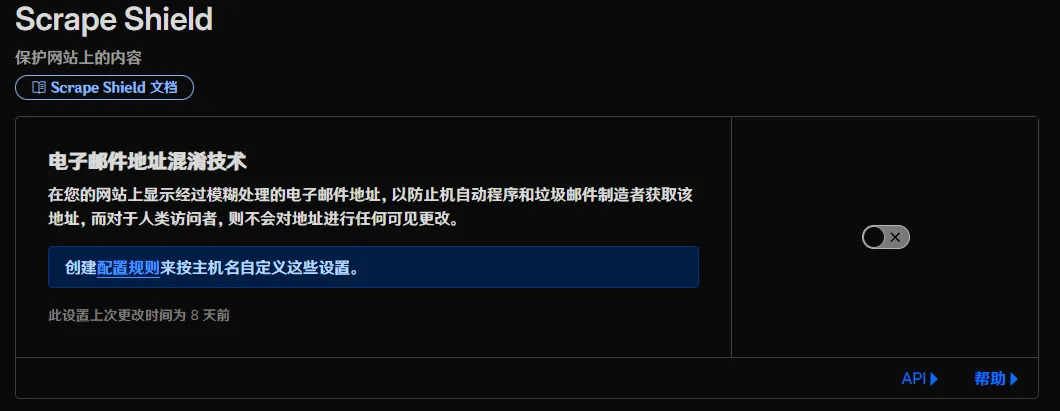
然后点开左边的“规则”,点击“概述”,创建规则,选择“URL 重写规则”。名称看你喜好来写,只要“如果传入请求匹配…”选择“自定义筛选表达式”,并点击“编辑表达式”,粘贴进去下面的第一个表达式,然后下面的“路径”选择“保留”,“查询”选择“重写到…”,选择“Dynamic”,粘贴下面的第二个表达式进去,就可以保存啦!当然了,那里面的 CFAcceptEncoding 是可以自己看喜好改的,只不过后面你要写规则的话可就得额外小心咯~
1 | (http.request.headers["accept-encoding"][0] wildcard r"*") concat(http.request.uri.query, "CFAcceptEncoding=", http.request.headers["accept-encoding"][0]) |
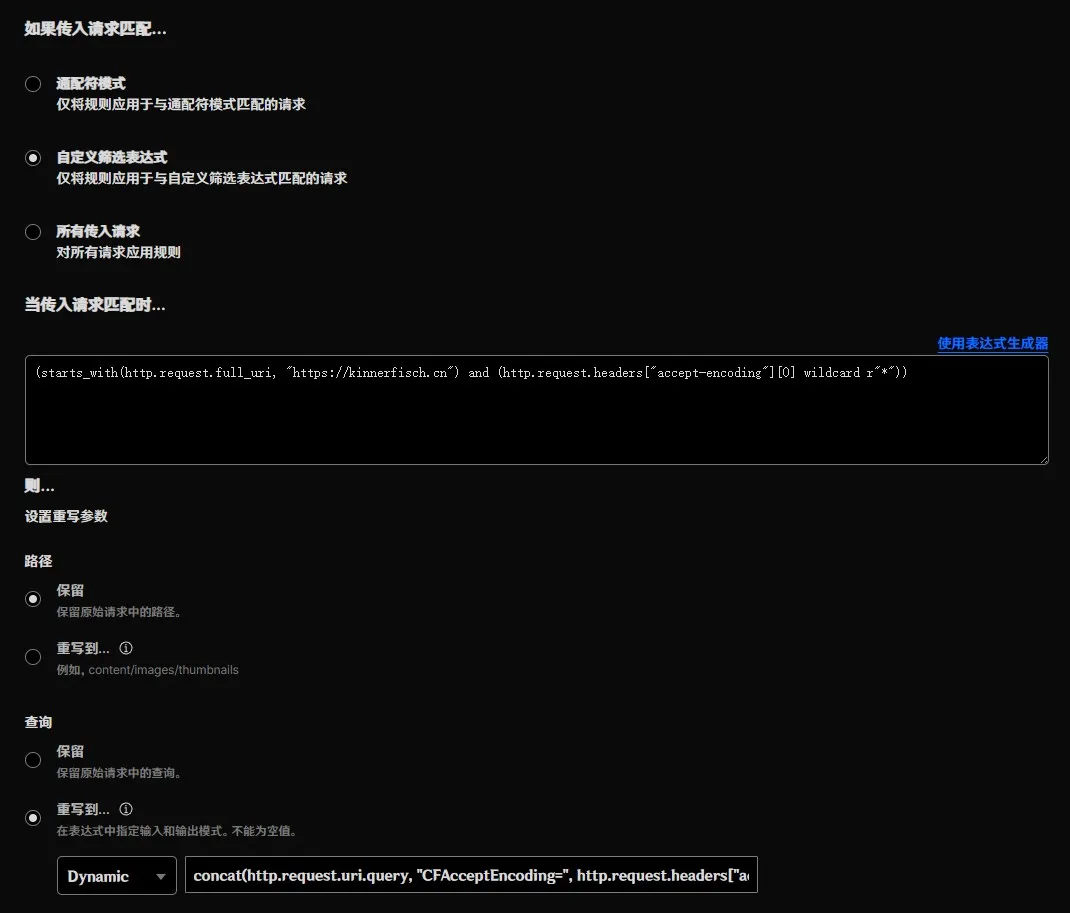
这一步主要是让你的源站知道客户端支持哪些编码,毕竟 Cloudflare 给你服务器发请求时用的 Accept-Encoding 可是固定的 br,gzip 呢。当然,我知道这种写法并不是很规范,但…图个方便还不行嘛!
接下来,我们要让 Cloudflare 大大完全听从我们源站的缓存指令,那就创建一条“缓存规则”,“缓存资格”选择“符合缓存条件”就行,其他的看你需要咯。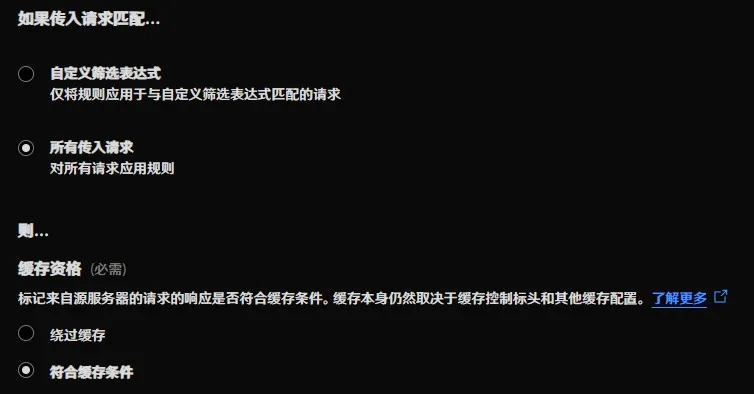
最后最后,我们再创建一条“压缩规则”,让 Cloudflare 对 gzip 友善点。这部分行为是真的很“独特”。这次“如果传入请求匹配…”只要“所有传入请求”就行,然后压缩选项选择自定义,只把一个 Gzip 丢进去就好了,别选多了,免得在 gzip 就是最优解的时候还要被 Cloudflare 换掉。别的压缩?别怕~ Cloudflare 会乖乖听话透传的~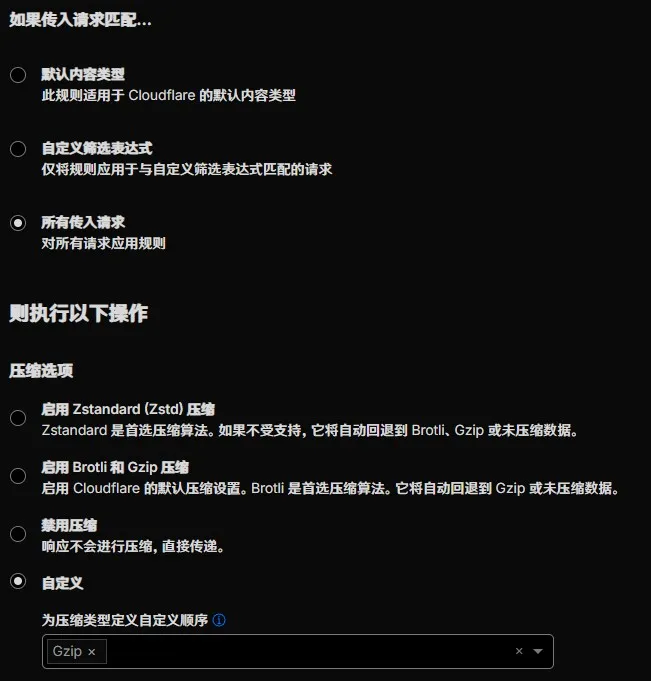
最后来看源站上的配置
Cloudflare 上配置完了,源站上也得要兼容啊!
有一点我们不得不承认的是,既然用了 Cloudflare,那么 deflate 是无缘了,毕竟他确实不支持,所以源站在处理来自 Cloudflare 时绝对不能使用 deflate 作为返回结果!然后呢,还需要你把写在 query 里的 CFAcceptEncoding 当作真正的 Accept-Encoding,并在服务器可能返回 br 和 zstd 时设置 Cache-Control 为 no-transform 以防止 Cloudflare 重新压缩。但要注意:在服务器返回 gzip 时,务必要取消掉 no-transform,否则浏览器会接收不到 Content-Encoding 头,导致乱码!
收尾
至此,这个问题算是被我解决掉了。这个方案不优雅,也谈不上“最佳实践”,但它至少让我明确了一件事:在 Cloudflare 前面,真正能完全控制内容压缩行为的,只有源站自己。如果你也和我一样,已经把文件压到极限,却还是被 Cloudflare “好心再帮一次”,那这条路或许能作为一个参考。
Cloudflare 的压缩逻辑并不是“错”,只是它的默认假设和我的需求完全不一致。在默认配置下,它更关心“通用性”,而不是“谁压得更小”。而当你真的在乎那点体积差异时,就只能自己把控制权拿回来。